1.2 언어 모델이 챗GPT가 되기까지
이 부분에서는 GPT 모델이 어떻게 발전해왔는지, 그리고 왜 챗GPT 같은 언어 모델이 특별한지 알아볼 거예요.
1.2.1 RNN에서 트랜스포머 아키텍처로
RNN(순환신경망)이란 'Recurrent Neural Network'의 약자인데요. 영어 뜻 그대로 '순환(Recurrent) 신경망(Neural Network)'이란 뜻이죠. 순환이란 순차적으로 돌아간다는 뜻이죠. 그래서, RNN은 데이터를 순차적으로 처리합니다. 다만, 순차적으로 처리하기에 데이터가 폭발적으로 증가하면 처음 데이터를 잊을 확률이 높아요
트랜스포머(Transformer)는 RNN의 한계를 해결하기 위해 개발된 아키텍처예요. Transformer라는 단어는 '변형'을 의미하는데, 이는 데이터를 순차적으로 처리하지 않고 한꺼번에 처리하는 방식을 통해 정보 처리 방식을 근본적으로 변형시켰기 때문이에요. 어텐션 메커니즘을 통해 모든 단어 간의 관계를 동시에 계산하면서, 길고 복잡한 문장도 효율적으로 처리할 수 있게 되었죠.

- 요약:
RNN은 데이터를 순차적으로 처리하지만, 트랜스포머는 어텐션 메커니즘을 통해 데이터를 한꺼번에 처리하여 긴 문맥도 기억할 수 있어요. - 용어설명:
- RNN(순환 신경망): 'Recurrent Neural Network'의 약자로, 순차적으로 데이터를 처리하는 방식이에요. 하지만 긴 문맥을 처리하는 데 한계가 있어요.
- 트랜스포머(Transformer): '변형'이라는 뜻으로, 데이터를 순차적으로 처리하지 않고 한꺼번에 처리하는 방식을 통해 정보 처리 방식을 근본적으로 변형한 아키텍처예요..
1.2.2 GPT 시리즈로 보는 모델 크기와 성능의 관계
GPT는 'Generative Pre-trained Transformer'의 약자예요. 여기서 주목할 것은 'T'가 Transformer를 의미한다는 점이에요. 즉, GPT는 Transformer 아키텍처를 기반으로 만들어진 모델이에요. GPT-1, GPT-2, 그리고 GPT-3로 이어지면서 모델의 크기(파라미터 수)가 커졌고, 더 많은 데이터를 학습하며 정교한 문장 생성이 가능해졌어요. 하지만 모델이 커질수록 학습 시간과 비용도 많이 필요해요.

- 요약:
GPT는 Transformer 아키텍처를 기반으로 만들어진 모델이며, 모델의 크기가 커질수록 성능도 향상되지만, 학습 비용이 많이 들어요. - 용어설명: GPT(Generative Pre-trained Transformer)
GPT는 'Generative Pre-trained Transformer'의 약자로, 데이터를 학습해 문장을 생성하는 모델이에요. 여기서 'T'는 앞서 설명한 'Transformer' 아키텍처를 의미해요.
1.2.3 챗GPT의 등장
챗GPT는 GPT-3를 기반으로 훈련된 모델이에요. 특히 대화 데이터를 학습해서 사람과 대화하는 능력을 극대화했어요. Transformer 아키텍처 덕분에 자연스러운 문맥 이해와 대화의 흐름을 이어갈 수 있는 능력이 뛰어나요.

- 요약:
챗GPT는 GPT-3를 기반으로 훈련된 대화형 AI 모델이며, Transformer 아키텍처 덕분에 문맥을 자연스럽게 이해해요.
실습 2: 트랜스포머 아키텍처 이해하기
이제 트랜스포머의 핵심 개념인 어텐션 메커니즘을 코드로 살펴볼 거예요. 어텐션은 트랜스포머에서 중요한 역할을 하는 부분이에요. 아래 코드로 간단한 어텐션 메커니즘을 구현해볼게요.
import torch
import torch.nn.functional as F
# 쿼리, 키, 값 벡터 정의
query = torch.rand(1, 3) # 쿼리 벡터 (1x3)
key = torch.rand(3, 3) # 키 벡터 (3x3)
value = torch.rand(3, 3) # 값 벡터 (3x3)
# 어텐션 점수 계산
attention_scores = torch.matmul(query, key.T)
# 소프트맥스를 통해 확률 분포로 변환
attention_probs = F.softmax(attention_scores, dim=-1)
# 최종 어텐션 값 계산 (값 벡터에 확률 가중치 곱하기)
attention_output = torch.matmul(attention_probs, value)
print("어텐션 점수:\n", attention_scores)
print("어텐션 확률:\n", attention_probs)
print("어텐션 출력:\n", attention_output)
이 코드는 간단한 쿼리-키-값 어텐션 메커니즘을 구현한 것이에요. 여기서 어텐션은 쿼리와 키 사이의 관계를 계산해, 어떤 단어에 더 주목해야 할지 결정하고, 그에 따라 값(Value)을 가중합해서 출력하는 방식이에요.
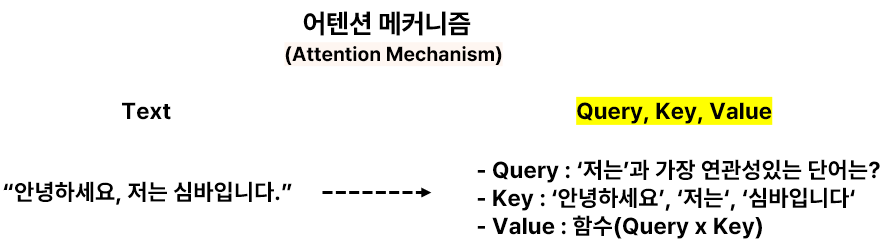
- 요약:
이 코드는 트랜스포머에서 중요한 어텐션 메커니즘을 구현해, 단어 간의 관계를 계산하고 중요한 단어에 더 집중하는 방법을 보여줘요. - 용어설명: 쿼리, 키, 값(Query, Key, Value)
쿼리는 현재 단어가 어떤 다른 단어에 주목해야 하는지 결정하는 벡터이고, 키는 모든 단어를 설명하는 벡터, 값은 그 단어와 관련된 정보를 나타내는 벡터예요. 어텐션 메커니즘에서는 쿼리와 키의 관계를 바탕으로 어떤 값을 더 중요하게 볼지 결정해요.
정리
- RNN은 데이터를 순차적으로 처리하지만, 긴 문맥을 기억하는 데 한계가 있었어요.
- 트랜스포머는 어텐션 메커니즘을 통해 데이터를 한꺼번에 처리하면서 RNN의 한계를 극복했어요.
- GPT는 'Generative Pre-trained Transformer'의 약자로, 'Transformer' 아키텍처를 기반으로 문장을 생성하는 모델이에요.
- 챗GPT는 GPT-3 기반으로 훈련된 모델로, Transformer 덕분에 자연스러운 대화 능력을 갖추고 있어요.
- 어텐션 메커니즘에서 쿼리(Query), 키(Key), 값(Value)은 단어 간의 관계를 계산하고 중요한 정보를 추출하는 역할을 해요.
'딥러닝(Deep Learning) > LLM' 카테고리의 다른 글
| 2-6. 인과적 언어 모델링, 마스크 언어 모델링에 대한 이해 (2) | 2024.10.30 |
|---|---|
| 1-3. LLM의 확장: 인식과 행동의 미래 (2) | 2024.10.02 |
| 1-2. LLM, sLLM, RAG에 대한 세상 제일 쉬운 설명. (0) | 2024.09.27 |
| 1. 딥러닝과 언어 모델링 (2) | 2024.09.22 |



